03-01-案例学习-手写数字识别任务
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别等领域,大大缩短了业务处理时间,提升了工作效率和质量。
- 任务输入:一系列手写数字图片,其中每张图片都是28x28的像素矩阵。
- 任务输出:经过了大小归一化和居中处理,输出对应的0~9的数字标签。
MNIST数据集
MNIST数据集是从NIST的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。Yann LeCun等人从SD-1和SD-3中各取一半数据作为MNIST训练集和测试集,其中训练集来自250位不同的标注员,且训练集和测试集的标注员完全不同。
MNIST数据集的发布,吸引了大量科学家训练模型。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集的误差不断下降(从12%下降到0.7%)。在研究过程中,LeCun提出了卷积神经网络(Convolutional Neural Network,CNN),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。
如今在深度学习领域,卷积神经网络占据了至关重要的地位,从最早LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等,人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
手写数字识别的模型是深度学习中相对简单的模型,非常适用初学者。正如学习编程时,我们输入的第一个程序是打印“Hello World!”一样。 在飞桨的入门教程中,我们选取了手写数字识别模型作为启蒙教材,以便更好的帮助读者快速掌握飞桨平台的使用。
构建手写数字识别的神经网络模型
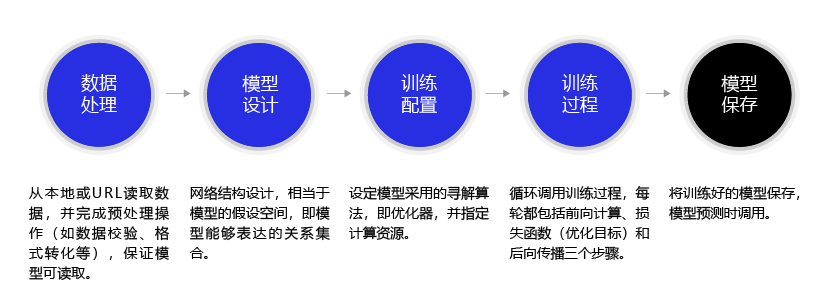
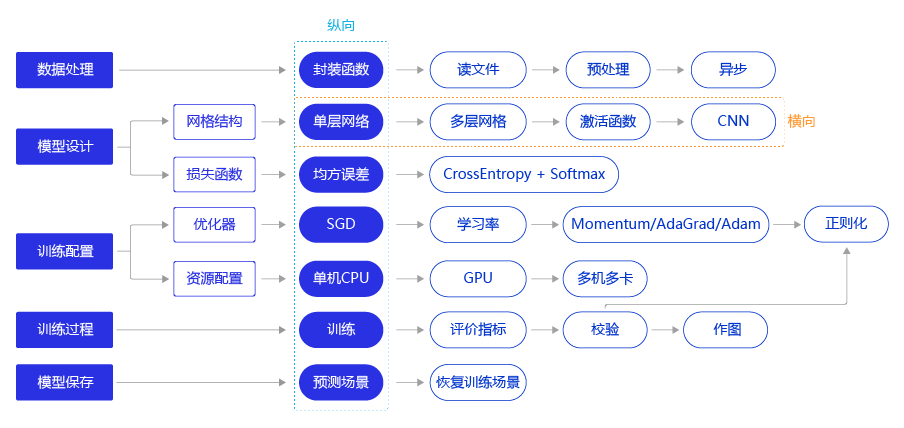
使用飞桨完成手写数字识别模型任务的代码结构如 图2 所示,与使用飞桨完成房价预测模型任务的流程一致,下面的章节中我们将详细介绍每个步骤的具体实现方法和优化思路。
数据处理
飞桨提供了多个封装好的数据集API,涵盖计算机视觉、自然语言处理、推荐系统等多个领域,帮助读者快速完成深度学习任务。如在手写数字识别任务中,通过paddle.vision.datasets.MNIST可以直接获取处理好的MNIST训练集、测试集,飞桨API支持如下常见的学术数据集:
- mnist
- cifar
- Conll05
- imdb
- imikolov
- movielens
- sentiment
- uci_housing
- wmt14
- wmt16
通过paddle.vision.datasets.MNIST API设置数据读取器,代码如下所示。
1 | # 设置数据读取器,API自动读取MNIST数据训练集 |
模型设计
在房价预测深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。在手写数字识别中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28×28)数据,输出为1维数据,如 图6 所示。
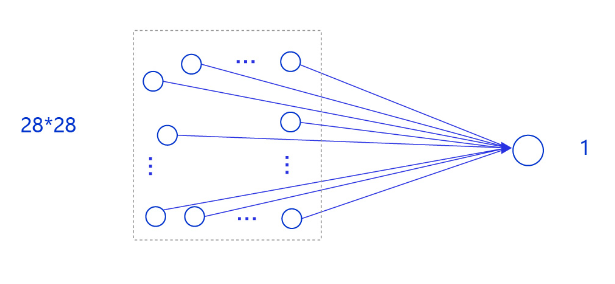
输入像素的位置排布信息对理解图像内容非常重要(如将原始尺寸为28×28图像的像素按照7×112的尺寸排布,那么其中的数字将不可识别),因此网络的输入设计为28×28的尺寸,而不是1×784,以便于模型能够正确处理像素之间的空间信息。
下面以类的方式组建手写数字识别的网络。
训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001)。
训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
- 声明实例
- 加载模型:加载训练过程中保存的模型参数,
- 灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
- 获取预测结果,取整后作为预测标签输出。
训练样本乱序、生成批次数据
- 训练样本乱序: 先将样本按顺序进行编号,建立ID集合index_list。然后将index_list乱序,最后按乱序后的顺序读取数据。
- 生成批次数据: 先设置合理的batch_size,再将数据转变成符合模型输入要求的np.array格式返回。同时,在返回数据时将Python生成器设置为
yield模式,以减少内存占用。
校验数据有效性
在实际应用中,原始数据可能存在标注不准确、数据杂乱或格式不统一等情况。因此在完成数据处理流程后,还需要进行数据校验,一般有两种方式:
- 机器校验:加入一些校验和清理数据的操作。
- 人工校验:先打印数据输出结果,观察是否是设置的格式。再从训练的结果验证数据处理和读取的有效性。
异步数据读取
上面提到的数据读取采用的是同步数据读取方式。对于样本量较大、数据读取较慢的场景,建议采用异步数据读取方式。异步读取数据时,数据读取和模型训练并行执行,从而加快了数据读取速度,牺牲一小部分内存换取数据读取效率的提升,二者关系如 图4 所示。
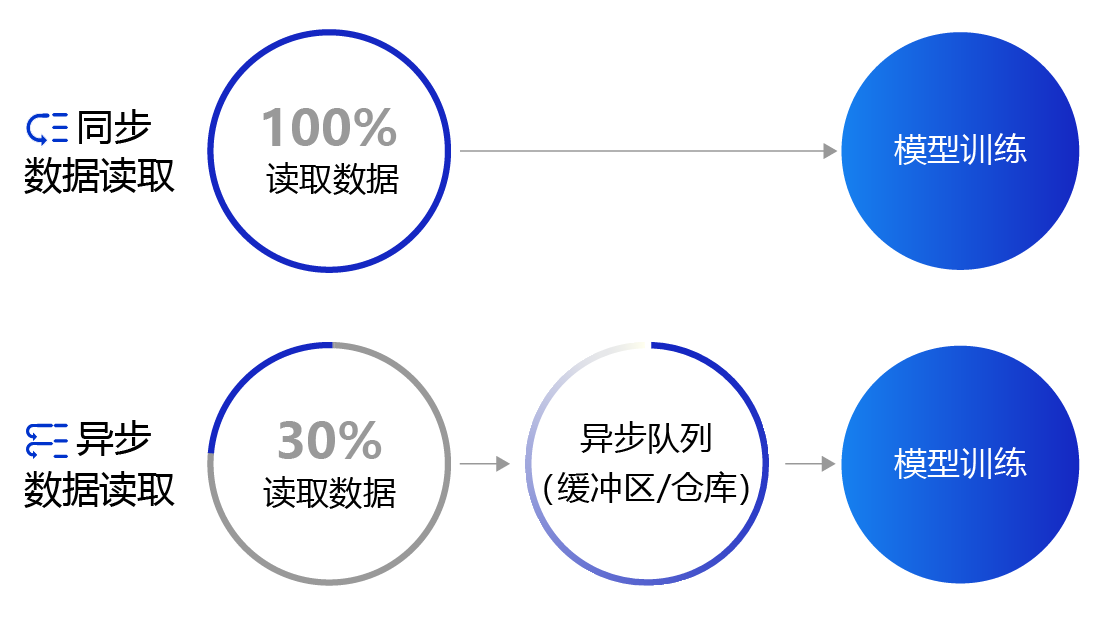
- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
使用飞桨实现异步数据读取非常简单,只需要两个步骤:
- 构建一个继承paddle.io.Dataset类的数据读取器。
- 通过paddle.io.DataLoader创建异步数据读取的迭代器。