I. 基准代码 一份基准代码,多份部署 II. 依赖 显式声明依赖关系 III. 配置 在环境中存储配置 IV. 后端服务 把后端服务当作附加资源 V. 构建,发布,运行 严格分离构建和运行 VI. 进程 以一个或多个无状态进程运行应用 VII. 端口绑定 通过端口绑定提供服务 VIII. 并发 通过进程模型进行扩展 IX. 易处理 快速启动和优雅终止可最大化健壮性 X. 开发环境与线上环境等价 尽可能的保持开发,预发布,线上环境相同 XI. 日志 把日志当作事件流 XII. 管理进程 后台管理任务当作一次性进程运行
微服务作为一个概念是满足12因素的多应用方案,是一个可以具体落地的方案。
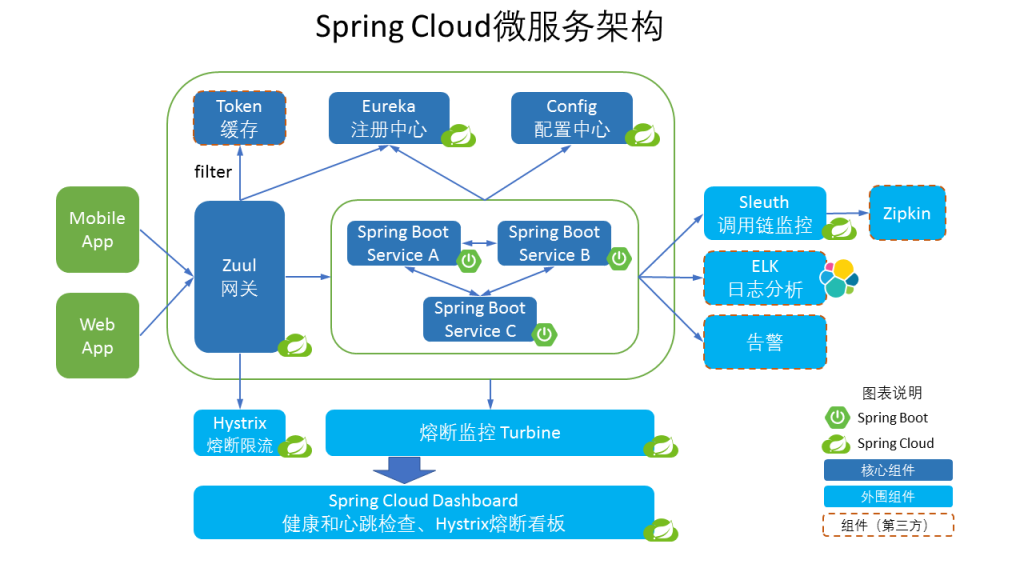
单体服务与微服务
单体服务,以 MVC 架构为例,业务通常是通过部署一个 WAR 包到 Tomcat 中,然后启动 Tomcat,监听某个端口即可对外提供服务。早期在业务规模不大、开发团队人员规模较小的时候,采用单体应用架构,团队的开发和运维成本都可控。存在问题如下:
部署效率低下。
团队协作开发成本高。
系统高可用性差。
线上发布变慢。
服务化,就是把传统的单机应用中通过 JAR 包依赖产生的本地方法调用,改造成通过 RPC 接口产生的远程方法调用。通过服务化,可以解决单体应用膨胀、团队开发耦合度高、协作效率低下的问题。
单体应用由于部署在同一个 WAR 包里,接口之间的调用属于进程内的调用。而拆分为微服务独立部署后,服务提供者该如何对外暴露自己的地址,服务调用者该如何查询所需要调用的服务的地址呢?这个时候你就需要一个类似登记处的地方,能够记录每个服务提供者的地址以供服务调用者查询,在微服务架构里,这个地方就是注册中心。